Rig file 분석 (2)
on
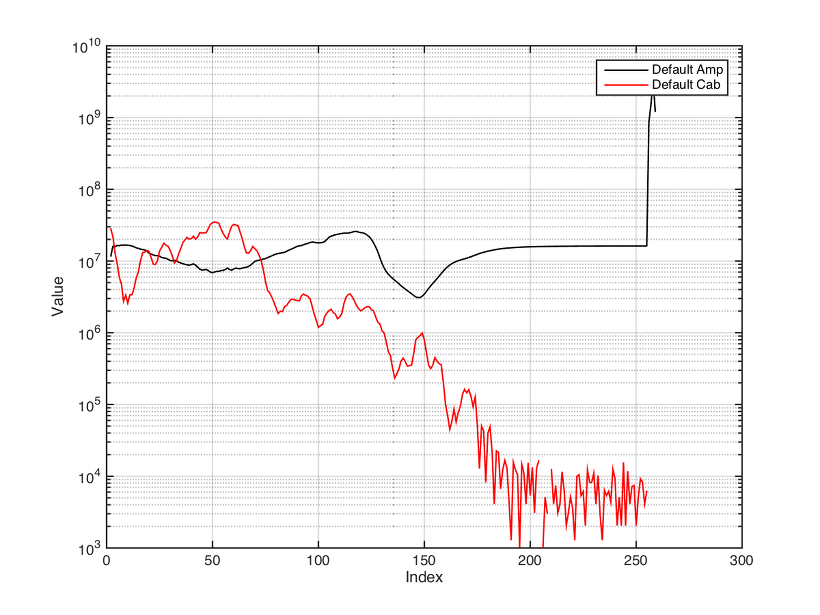
Rig file을 열어보면 큰 데이터 블록이 2개 있다고 지난 번에 얘기했던 것 같다. rig file하나만 열어보고 전체 알고리즘을 알 수 있다면 좋겠지만, 사실 데이터가 이러이러 하다를 통해서 알고리즘을 유추할 수 밖에 없다.각각의 데이터블록은 266*4+1의 데이터로 되어있고, 4는 32bit word로 실제로 24bit number를 나타낸다. 266개의 유의미한 데이터를 가지고 있는 것으로 볼 수 있는데, 이중 256개만 암호화가 되어있다. 256이란 수가 뜻하듯 FFT과 연관된 수 일것 같고 언뜻 생각해봐도 256 point로 나타낸 주파수 특성이겠구나 하게 된다. 그러면 나머지 10개의 데이터가 남는데, 여기서 3개는 암호화하는데 쓰여지고 7개가 남는다. 이것들은 EQ라든가 앰프시뮬과 별 개의 요소를 컨트롤하는데 쓰이는 값으로 6개가 들어가고 1개가 모르는 값이 된다. 따라서, 이 두 개의 데이터 블록은 그 값이 그대로 외부에 노출되었을 때, 어느 누가 보든 의미있는 값으로 보이기 때문에 조금만 파고들어가면 알고리즘이 탄로날 수 있게 될 것을 염려하여 암호화를 해놓은 것이 아닐까 생각한다. 불행히도 그들이 공개한 앱 몇 개를 열어서 리버스 엔지니어링을 해보면 암호를 쉽게 풀어낼 수 있다. 말이 쉽게지 assembly instruction을 가지고 원래의 코드를 유추한 뒤에 암호가 제대로 해제될 때까지 실험해봐야 되니까 아무나 할 수 있는, 또 손쉽게 1-20분만에 뚝딱 할 수 있는 일은 아니다.신기하게도 cabmaker라고 하는 kemper의 외부 IR 변환 프로그램도 그렇고, rig file도 그렇고 뭔가가 항상 pair로 되어있다는 것이다. 대충 유추하기로는 하나는 캐비넷을 뺀 앰프의 응답, 또 하나는 스피커의 응답을 갖고 있을 것으로 보여진다. 그 이유는 파일이름이 그렇게 붙어있기 때문이다. 하난 default amp로 붙어있고 하난 default cabinet으로 되어있다. 왜 이걸 두개로 해놓았느냐 따지고 들면 아마도 cabinet on/off을 하기 위함이 아니었을까 한다. 그런데 어떻게 마이크로 받은 입력을 이용해서 시스템을 분석했는데, cab을 on/off할 수 있느냐라는 질문을 할 수 있을 것 같다. 마이크로 얻어지는 것은 amp + cab + mic로 이루어진 시스템의 특성이지 개개의 시스템 특성이 아니기 때문이다.어쨌든 아래의 그림을 확인해보면 좋을 것 같다.
첫번째 그림은 cabmaker에 들어있는 두 개의 시스템 특성 데이터이다. 어떤 것인지 확실히 알 수는 없지만, 대략 그 의미는 파악이 된다. 곡선으로 보건데 캐비넷 특성 곡선은 확실히 스피커 캐비넷의 주파수 특성을 나타내는 것임을 알 수 있다. 256 point로 되어있으니까 더 이상 의심을 할 여지도 없다.
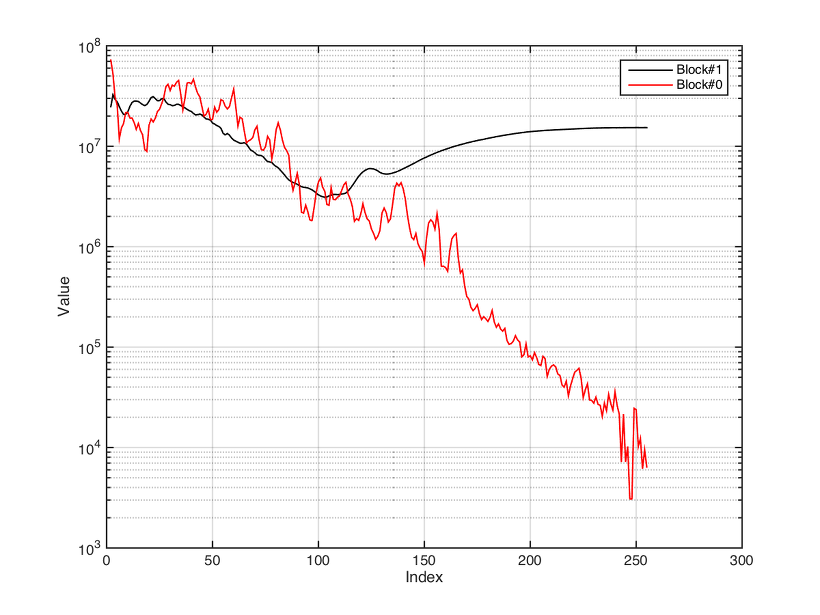
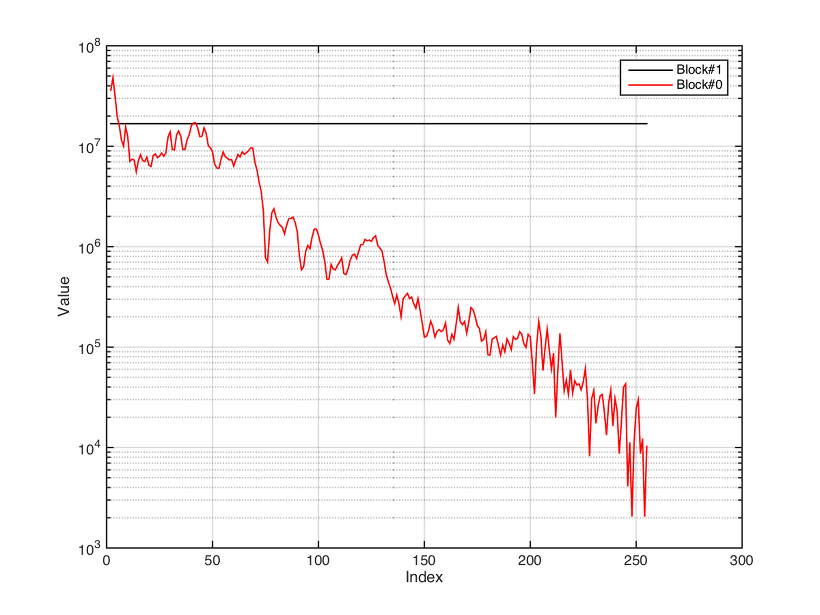 JCM800, Clean
JCM800, Clean
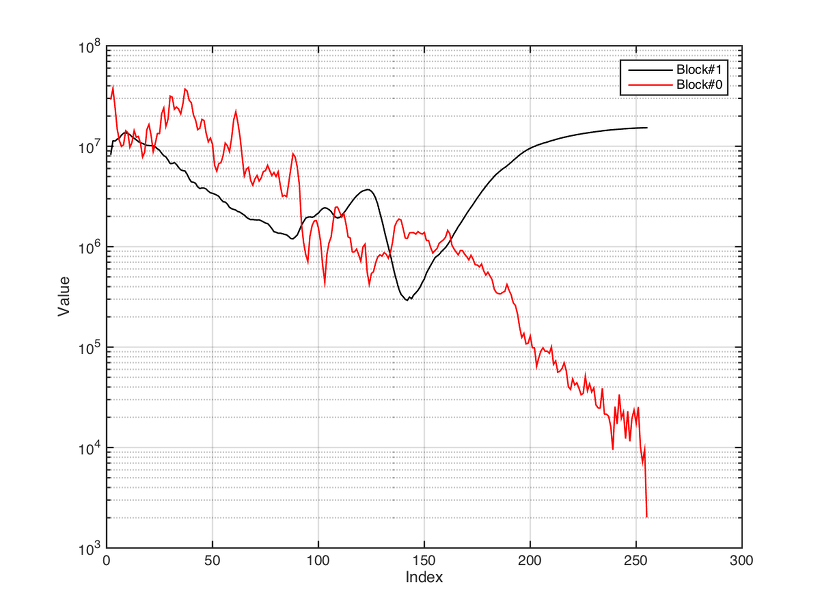
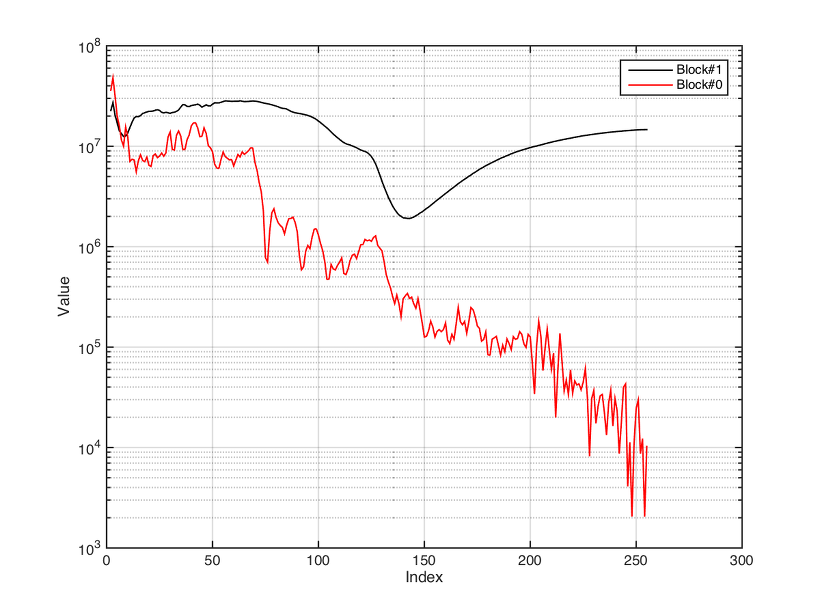 JCM800, Fully cranked
JCM800, Fully cranked
내친 김에 JCM800으로 올라온 두 개의 rig file을 관찰하기로 하자. 하나는 clean이고 나머지는 full cranked up이라고 해놓은 것이다. 그림을 보면 block 0는 cab의 주파수 특성을 나타내는 데이터를 담고 있는 것으로 보여지고, block 1은 Cab을 뺀 나머지의 주파수 특성을 나타내고 있는 것으로 보여진다. clean은 말 그대로 flat한 반면 full cranked up의 경우는 어떤 곡선의 모양을 띠고 있는 것으로 볼 때, 이것은 profiling을 할 때 clean이냐 아니냐를 물어 볼 때 결정된 것이 아닐까 생각된다.Full cranked up인 경우의 곡선을 보면 캐비넷 특성을 곡선에 비해 생각보다 많이 smooth한 경향을 볼 수 있다. 이 둘을 비교하면 유추되는 특성이 있다.* gain이 많든 적든 block 0의 응답이 비슷하게 나왔는데, 여기서 미루어 짐작하기로는 block 0은 시스템 전체의 특성이 아닌 비선형성이 거의 없는 상태의 amp EQ + cab + mic 특성이 반영된 것으로 유추된다. * block 1의 데이터는 clean과 dirty의 경우를 비교해 보면 주파수에 따른 distortion이 일어나는 threshold?로 이해가 된다. clean일 때는 이 값이 매우 높게 설정되어있고 전 영역에 걸쳐 일정하게 되어있는 반면 dirty의 경우는 주파수에 따라 다르고 clean에 비해 낮은 값으로 되어있다. 다시 말해 dirty channel에서는 낮은 크기의 입력에 saturation이 일어나는 것을 알 수 있고, 중간 음역대일 수록 더 낮은 진폭에 saturation이 일어나는 것을 의미하는 것으로 유추된다. 즉, 이러한 곡선 모양대로 입력을 boost한 뒤에 saturate하면 되지 않을까 하는 추측도 아울러 가져본다.
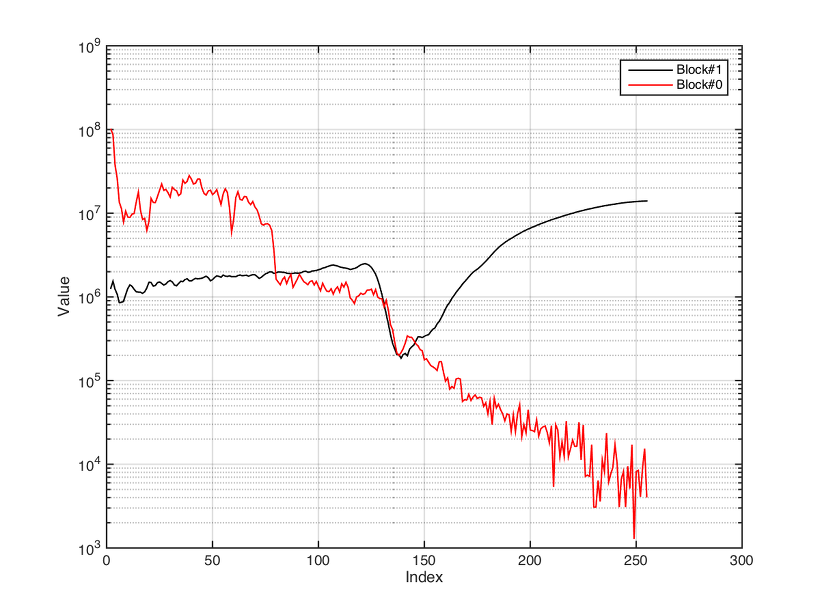 JCM800, 2203
JCM800, 2203
 Mesa RoadKing
Mesa RoadKing
 Mark IIc Lead
Mark IIc Lead
나머지 몇 가지 앰프들의 예를 더 보기로 하자. 그림에서 보는 바와 같이 block 0은 캐비넷의 응답을, block 1은 distorted channel일 때 부각되는 주파수 특성을 나타낸 것임을 여지없이 확인할 수가 있다. 따라서, 지금까지 확인된 결과만을 가지고 정리하면 다음과 같다. * KPA는 2개의 시스템 특성 데이터를 가지고 앰프 특성을 프로파일링 한다. 하나는 캐비넷의 특성, 나머지는 비선형성이 발생할 때의 추가적인 주파수 특성으로 나누어 분석한다. * 266개의 데이터 중에 256개를 분석했고, 3개는 암호화를 위해 쓰여지고, 6개 정도의 값은 임의의 설정값 (프로파일링 시 입력하는 EQ 값 등등)으로 보여지고 1개가 무슨 의미를 가지고 있는지 파악이 되지 않는다. * 이 결과 만으로는 앰프를 모두 프로파일링하기 어려운데, 가장 중요한 비선형성을 어떻게 얻어냈느냐가 관건이다. 지금까지 분석해놓은 것으로만 봐도 앰프의 비선형성을 매우 세밀하게 프로파일링 하진 않고 단순한 비선형 모델에 캡 특성을 반영하는 정도가 아닐까 유추된다.이를통해 rig 파일로부터 캡 IR을 역환산 해낼 수는 있을 것 같다. 또한 대략적으로 유추한 시스템을 가지고 소위 rig file player를 만들어 플러긴으로 실험해 볼 수 있을 것 같다. 아마도 Kemper에서는 이것을 경계했지 싶다. 계산량도 얼마안되는데다 일반 사용자가 프로파일링 기능을 갖추고 있을 필요도 없기 때문에 알짜를 플러긴으로 뽑아내면 대부분 플러긴을 쓰지 장비를 구입하려 하지 않을 뿐더러, 이게 그냥 무료로 돌게 되면 사실상 ‘끝장’이 나는 거다. 다시 반복하는 이야기지만, 비슷한 일을 하는 기기가 없었기에 여태도 비싼 값에 팔리고 있을 뿐이지, 기계 자체의 수행 능력이나 알고리즘은 일반인의 기대에 훨씬 미치지 못하는 장비라고 난 평가하고 싶다. 그렇게 따지면 fractal audio의 장비는 다르냐 하겠지만, 난 오히려 프랙탈의 장비에 손을 들어주고 싶다. KPA는 기본적으로 saturation에 의한 aliasing에 대한 고려가 덜 되어있다. 장비를 가지고 있는 분은 한번 실험해보기 바란다. 게인을 잔뜩 걸고 고음 프렛을 튕긴 후 아래위로 밴딩해보라. 분명 내가 원하지 않은 음이 같이 움직임을 느낄 것이다. 내 예상으로는 오버샘플링도 전혀하지 않거나 많아봐야 x2쯤 헀을 것으로 보여진다. 장착 되어있는 DSP가 그렇게 많은 일을 할 수 있는 고성능 DSP가 아니다. 시스템을 이렇게 분석해놓고 클로닝을 했다고 떠벌리는 자체가 귀속임일 수 있는 것인데, 사용자들은 엄청난 장비인양 떠받들고 있고 정말로 다양한 미사여구로 칭찬하고 있는 걸 보면 귀보다 입이 발달한 사람들이 더 많은 것 같기도 하다. 비선형성이야 대충 흉내를 낸다고 할지 몰라도 다이내믹한 특성 (컴프레서적인 특성)을 반영하긴 시스템의 모델자체가 그걸 지원할 수도 없고, 프로파일링 단계에서 측정하지도 않는다. 이미 설명했다시피 프로파일링 단계에서 가장 중요한 것은 캐비넷의 특성을 측정하는 것과 하모닉의 비율을 분석하는 과정이다. 언제 break-up이 이루어지는지에 대한 측정이 있는데, 그 값을 어떻게 반영했는지 알아봐야한다.