GPU에 대해서 알아볼까?..
on
사실 몇년 전에 알아보고 싶었던 테마인데 인생이 원하는 대로 흘러가지 못하다 보니 잠시 멀어져버렸던 것 같다. 그러나! 이제 알아볼 수 있게 되었다!
왜 GPU에 대해서 알아보아야 되나?
GPU는 이제 너무나도 흔한 컴퓨터 부품이고 하는 일도 많은데 그것이 정확히 무엇을 하고 있는지는 잘 모른다. 그래서 알아봐야 된다라고 말하면 뭐랄까 너무 교양스러울 수 있다. 근본 목표는 GPU의 아키텍쳐를 어떻게 응용할 수 있을까를 모색하는 것이다. 왜? 좋은 점이 분명히 많을 것이니까.
GPU의 아키텍쳐
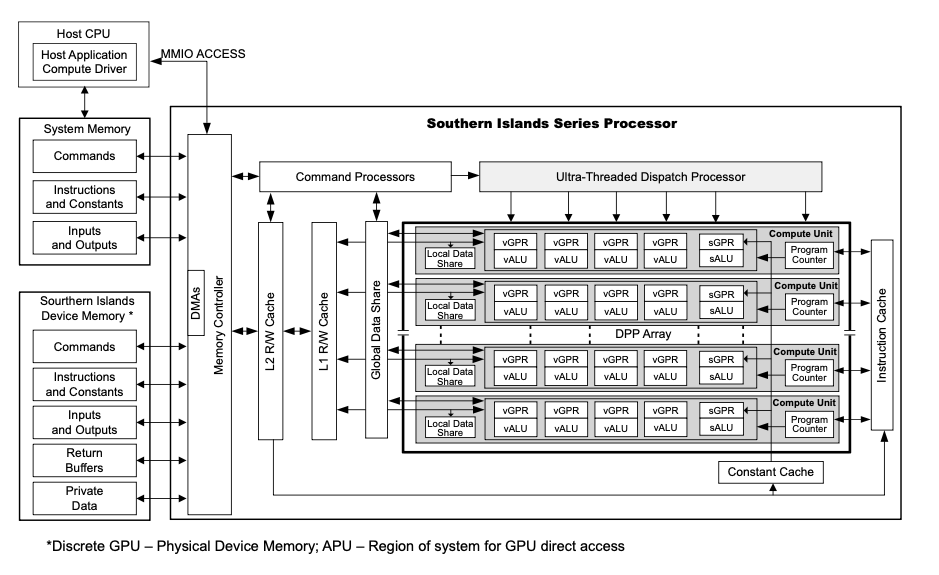
그림에서 보이는 블록 다이어그램을 보면 쉽게 이해가 될런지 모르겠는데, ALU fabric? CPU array? ALU matrix? 등등으로 불리우는 구조다. 수 많은 연산 로직을 병렬로 주욱 늘어놓고 데이터 교환의 효율성을 높이기 위해 cache를 두고 또 프로그램을 구동할 수 있게끔 instruction을 정의하고 그것을 decoding하는 로직도 있고 해당 instruction에 따라 외부의 데이터를 어떻게 load하고 수행 결과를 write하는지 잘 묘사하고 있다.
정확히 어떤 스펙으로 설계해야 하는지는 모르지만, 어떤 요소가 필요한지 아주 잘 보여주고 있다.
1) ALU array
그냥 말 그대로 ALU array다. 대개 ADD/SUB/MUL의 연산이 가능하다. 경우에 따라 division을 수행하는 경우도 있는데, 그것은 설계 방법에 따라 다르다. division을 multiplier의 loop로 꾸미는 경우도 있으니까. 어쨌든 division은 어떤 경우에도 최대한 꺼리는 연산이다.
또 응용 분야에 따라서 ALU는 floating point로 혹은 fixed point로 설계 되기도 한다.
2) Cache
Cache는 data cache와 instruction cache로 나뉜다. 가장 중요한 기능은 최대한 외부 memory와의 access를 줄여서 cycle count를 최소로 만들기 위함이다. 외부 memory를 access하는 것은 single cycle로 할 수 없으니까 그래서 latency가 발생하고 efficiency가 떨어질 수 밖에 없게 되니까.
중요한 것은 모든 device들은 병렬로 개별적으로 구동되기 때문에 단지 외부 memory를 access하는데 많은 cycle이 소요되니까 무조건 나쁘다고 할 수는 없다. application에 따라 효과적으로 scheduling을 하면 최대효율로 구동할 수 있다. 그러나 내내 external memory를 access하게 되면 반드시 효율이 떨어질 수 밖에 없고 한번 로드된 데이터를 재활용하는 경우가 빈번히 발생할 수 밖에 없기 때문에 cache는 필수 요소이다.
3) Registers
그림에서 보면 GPR (generator purpose registers: 소위 범용 레지스터)에 해당한다. register라는 것은 흔히 말해서 단숨에 가져다 쓸 수 있는 변수 공간? 그쯤 되겠다. 그러니까 내가 A * B = C라는 연산을 하겠다면, 외부 메모리로부터 값을 읽어서 cache에 가져다 놓고 빠르게 계산을 하기 위해 최종적으로 A, B register에 가져와야 한다. register는 단박에 ALU에 연결될 수 있는 메모리 공간이다. 마찬가지로 결과가 씌여지는 C도 그러하다.
4) array architecture
application에 따라 ALU array를 어떻게 구동할지 다 달라지게 된다. 단숨에 병렬 연산을 해야된다면 이러한 구조가 도움이 되는데, 반면에 연산이 순차적으로 이루어지는 경우가 많다면 이러한 구조가 효율이 떨어질 수 있다. 그러나! 다루어야 하는 데이터의 양이 굉장히 많다보면 그 데이터의 context에 따라서 병렬화가 가능해지므로 해당 연산기 구조는 최대 효율로 구동이 가능하다.
이를테면 ray tracing을 하는 경우 모든 ALU를 개별적인 dot의 rendering의 좌표를 계산한다거나 해당 dot의 RGB 값을 게산하는데 이용한다고 하면 모든 점에 대한 연산은 병렬화가 가능하므로 효율이 극대화될 수 있다. 반면에 어떤 행렬 연산을 구현해야 한다고 하면 개개의 element간의 곱셈은 병렬화가 가능하다 하더라도 그 결과들은 모두 서로 더해져야 되므로 serial한 연산에 유리한 구조로 설계되어야 한다. 일단 지금의 구조는 graphic처리에 적합하고 하나의 명령어를 통해서 모든 array의 element를 구동할 수 있게끔 설계 하는 것이 유리한데, 우리는 이것을 SIMD (single instruction multiple data)라고 말한다.