GPT model...
on
요즘 Transformer 모델을 일주일 정도 집중해서 들여다보고 있다.
개념이나 데이터의 흐름으로 먼저 이해해보려 하기보다는,
논문을 먼저 읽고 개념을 받아들이려 하는데,
내면의 저항이 꽤 심해서 적지 않은 노력이 들어간다.
아마 그 이유는, 오랫동안 새로운 걸 거의 공부하지 않고,
내가 이미 알고 있는 것들만으로 세상을 해석하고 살아온 시간이
꽤 길었기 때문인 것 같다.
이 새로운 개념을 받아들이기 위해선 분명 노력이 필요하고,
그 문턱을 넘어서야 앞으로 계속 등장할 새로운 개념들도
제대로 받아들일 수 있다는 일종의 위기감이
게으른 나를 계속 붙들어놓고 있다고 느낀다.
Deep Learning 분야를 오랜 시간 멀리했던 데다가,
블록 다이어그램, 데이터 흐름, 데이터의 크기와 차원 같은 개념들을
내게 익숙한 신호처리 이론처럼 받아들이려 하다 보니
생각보다 쉽지 않았다.
또 중요한 것은
Neural Network이 학습과 추론을 수행한다는 사실을 염두에 두지 않으면,
이 모델의 동작이 제대로 이해되지 않는다.
특히나 각각의 동작에 대해서
의문을 품고 스스로 질문하지 않으면,
그렇게 풀리지 않은 의문들이 많이 쌓여서
전체적인 그림을 이해하는 걸 계속해서 방해한다.
원래 이 분야에 익숙한 사람이라면
논문 하나만으로도 그 아이디어를 쉽게 이해할 수 있겠지만,
그렇지 않은, 다른 백그라운드를 가진 사람들은
여기저기 문헌을 찾아보고, 용어의 개념을 실습을 통해 학습하면서
천천히 감을 잡아가는 수밖에 없다.
그렇게 이 분야의 입문을 위해 매일 매일 꽤 열심히 노력했음에도,
윤곽을 읽어냈구나 싶은 단계에 이르는 데도
꼬박 일주일이라는 시간을 썼다.
무엇보다 큰 도움이 된 건 역시 NVIDIA GPU였다.
나는 지금의 이 거대한 변화의 중심에 NVIDIA가 있었다고 생각한다.
이토록 빠르고 강력한 계산기가 없었다면,
지금 같은 상황에 이르기까지 훨씬 오랜 시간이 걸렸을 것이다.
왜 transformer인가?
사람의 언어는 문장을 구성하는 단어들과 그들의 순서상에 강력한 dependence가 있는 sequence이다.
이런 경우를 다루려면 feedback이 있는 네트워크를 이용하는 방법을 생각할 수 있는데,
이러한 경우에는 단어와 단어간의 관계를 따지기도 애매하고
데이터의 처리는 무조건 sequential하게 해야 하기 때문에
병렬화를 할 수가 없어서 학습/추론 속도를 하드웨어 증설로 개선할 방법이 없다.
쉽게 말해서 single core CPU score가 엄청나게 높아지지 않는 이상엔
뚜렷한 성능 개선을 볼 수가 없는 거다.
그러나, transformer는 병렬화를 하면서도 문장내의 단어와 단어와의 관계를 고려한 인식을 가능하게 했다.
attention이란 구조가 이걸 가능하게 만들었다.
문장안에서 단어와 단어간의 관계, 순서에 대한 정보를 가지고 인식을 할 수 있게 도와주었기 때문이다.
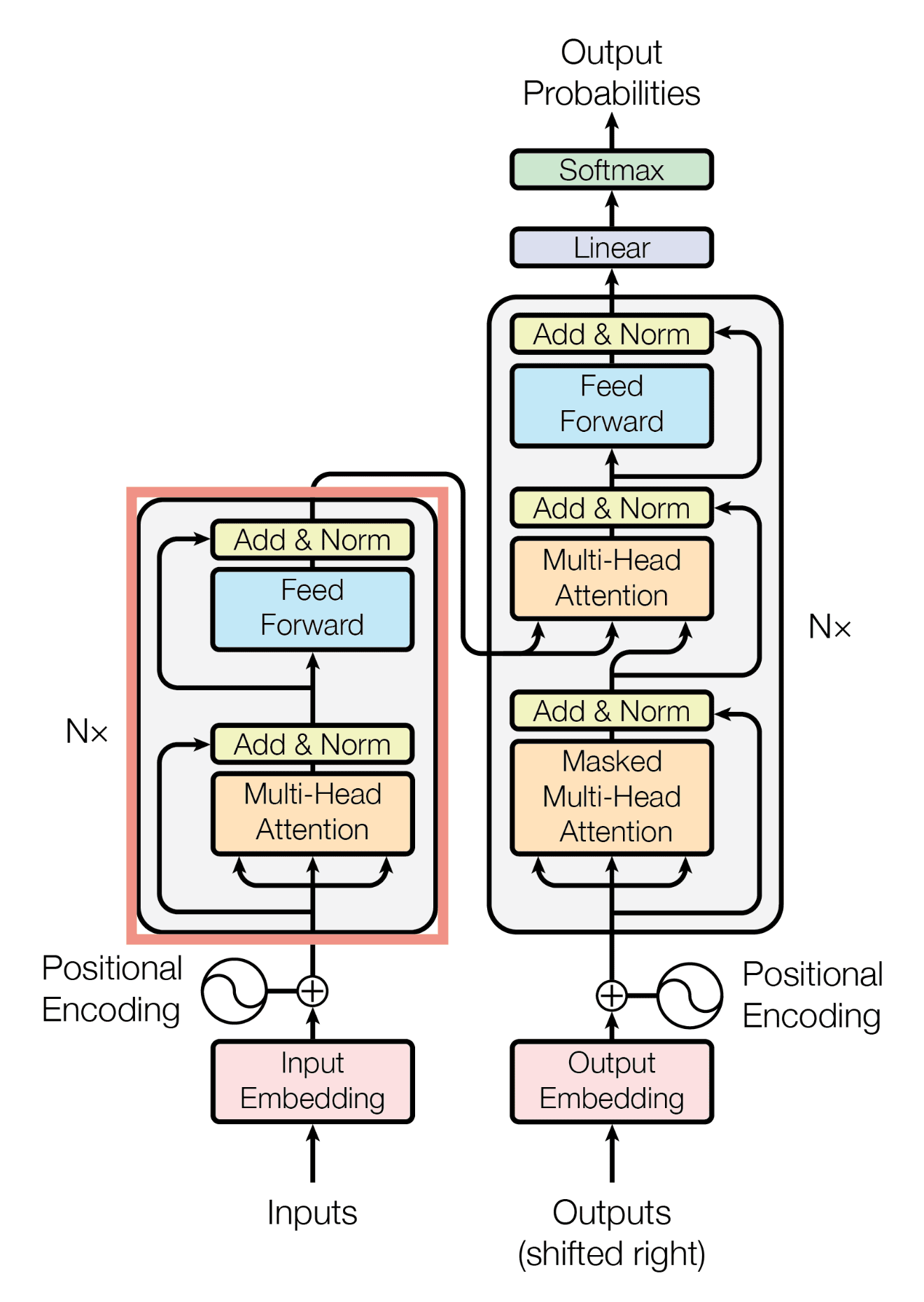
transformer의 구조
transformer라는 것이 처음 나온 것은 번역기를 만들면서 부터라고 한다.
논문을 보면 영어를 독일어로 번역하는 모델을 만들려고 하다 나온 것이란다.
여기에 나오는 전체적인 구조(아래 그림)는 어떤 기본적인 개념을 학습하는데 너무 큰 노력이 들어가게끔 그려졌다.
그런데, 이 방법 말고 더 좋은 방법으로 설명하기도 쉽지 않다고 생각한다.
내가 가장 먼저 들은 이야기가 ‘transformer가 생성형 AI의 시초가 되었고 그것은 encoder와 decoder로 구성되고….’ 였다.
그래서 뭘 먼저 알고 이해해야 하는지 혼돈이 일어났다. 뭔지도 모르면서 용어만 받아들이기 앞섰기 때문이다.
여기서의 encoder와 decoder는 (우리가 흔히 알고 있는) channel encoder/decoder의 개념과는 좀 다르다.
아래 그림은 이 구조에서 가장 중요한 부분이다. 일단 하나의 입력으로부터 3가지로 다르게 변환한 값을 가지고 처리하는데, 첫번째와 두번째는 서로 곱한 뒤에 어느 정도의 유사도가 있는지 확률로 계산하고 그것을 바탕으로 나머지 하나에 적용해서 확률상으로 높은 것은 키우고 나머지는 줄여주는 그런 일을 하는 것으로 구성된다.
이것을 scaled dot attention이라고 하는데, 일단 어떤 것을 중요하게 봐야하는지를 attention이라고 하고 그것을 dot product와 scale로 얻어냈기 때문에 scaled dot attention이라고 한다.
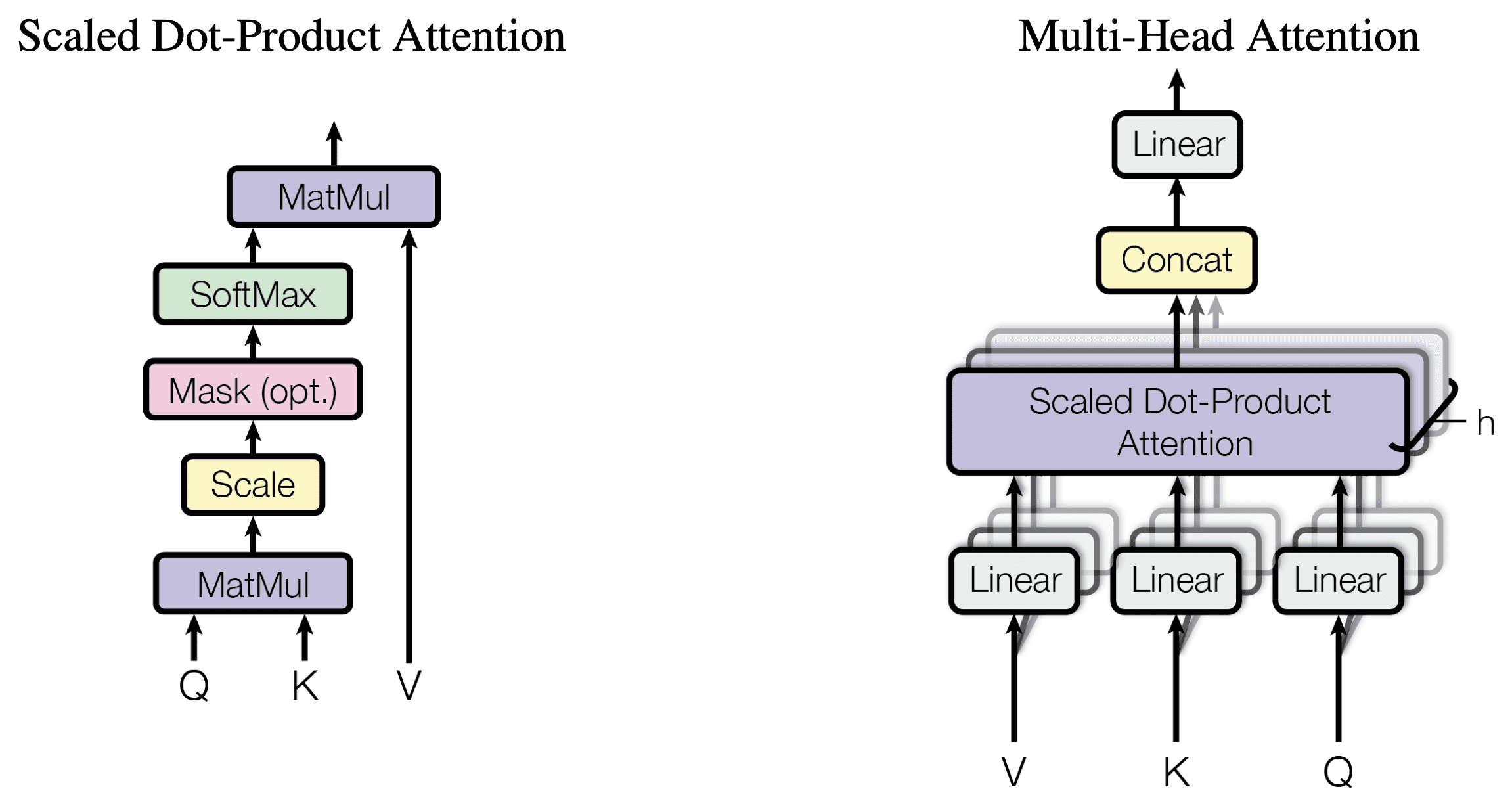
이것을 병렬로 여러 개로 확장을 시켜내면 그것을 multi-head attention이라고 한다. 그러니까 하나의 입력(=문장)에 대해서 이렇게도 보고 저렇게도 보고 해서 어떤 것을 강조해서 바라봐야 될지를 계산해 내는 것이다.
다음은 이것을 이용한 GPT-2 model을 나타낸 것이다.
이 그림도 앞의 그림들과 비교하면 구조가 큰 차이가 없다. multi-head attention을 기본 요소로해서 돌아가도록 되어있다. 일반적으로 layer는 12개 head의 수를 12개로 해서 가져간다고 한다.
이걸로 뭘 하겠다는 건가?
가장 궁금한 것은 이걸로 뭘하지? 하는 것이다. 뭘 넣으면 뭐가 나오는 거지?
이것은 일종의 (다음) 단어 예측기라고 해야 맞다. vector(?) predictor다.
단어는 단어 그대로의 스트링이 들어가는 게 아니라 그것을 어떤 숫자/벡터에 매핑하고 (이걸 이들 용어로 embedding이라고 한다) 그것을 넣어준다. 망에서는 모두 벡터로 처리되고 결과로 나오는 것도 마찬가지로 단어를 의미하는 벡터가 된다. 그것을 토큰이라고 하는 것이다.
사람이 사용하는 언어의 단어를 실수로 매핑한다고 하면 차원이 높은 벡터를 쓰지 않고 그냥 scalar 값 하나로 매핑해도 될 것 같은데, 단어의 수가 많아지고 처리해야할 개념의 양이 많아지게 되므로 이것을 벡터로 만들어버린 것으로 이해한다. 최근의 LLM은 12288 개의 길이를 갖는 벡터로 토크나이징을 한다고 하니까. 구체적으로 단어와 단어간의 euclidean distance를 멀게 하고 문장 내에서 연관관계라거나 언어적인 차이를 쉽게 분간하기 위해서 어떠한 vocabulary와 어떤 매핑방법을 쓰는지는 아마 한참이나 뒤에야 알게 될 것 같다.
본론으로 돌아와서 이 장치는 토큰 (=단어 혹은 중요 문장부호) 혹은 토큰의 세트 (문장)를 입력하면 학습과정에서 얻어진 내용을 토대로 다음에 나올 가능성이 매우 높은 토큰을 예측해내는 장치인 것이다. 당연히 학습할 때에도 어떤 문장을 넣어주고 예상되는 정답이 한 토큰 다음의 입력이 되도록하는 것이다. 그러니까 이 장치를 통해서 얻고자 하는 것은 어떤 맥락을 가진 sequence가 주어졌을 때 다음에 나와야 할 가장 높은 확률의 sequence를 예측하는 것이다. p
신호처리 이론으로 생각해보면 일종의 prediction filter?인 셈인데, 언어는 시간에 따라 변화하는 bandlimited random signal과는 다르기 때문에 쉽지 않다. 이 문제를 아마도 lattice predictor처럼 구성한다거나 하는 식으로 시도했을 것 같기도 하고, 앞서의 입력이 이후에 영향을 미치게끔 RNN(LSTM/GRU)를 이용해서 시도했을 것 같기도 하다. 그런데 transformer라는 구조에 정착하여 현재 좋은 결과물을 내고 있고 이와 확연히 다른 구조의 것은 잘해봐야 diffusion model이 전부인 것으로 알고 있다.
관련 용어/파라미터
- batch size
한번에 얼마나 많은 시퀀스를 입력하는지를 정한다.
- embedding size
하나의 토큰이 변환되어 나타나는 벡터의 길이
- number of heads
하나의 토큰이 벡터로 들어오면 이 개수만큼 잘라서 병렬로 처리한다. embedding size가 768이고 number of heads가 12라면 각각의 attention에서는 길이가 64인 벡터들을 처리하게 된다. 결과적으로 64개씩 나눠서 12개의 attention score가 얻어지게 된다.
- number of layers: transformer layer (=attention + linear layer)의 개수를 나타낸다.
입출력의 크기
크기를 계산해보면서 내부에 있는 요소들이 어떻게 영향을 주고 받는지 알 수 있다.
- 입력: batch size(B) x sequence length(T) x embedding size (d)
- Matrix for Q, K, V: d x d –> h x dh x h x dh
- Q, K, V: B x T x d –> B x h x T x dh (=d/h)
- attention score: QK^T –> B x h x T x T : 한 문장 내에서 주요한 영향을 미치는 것들이 어떤 것인지 알려준다. 그게 head 별로 되어있다.
현재의 토큰은 과거의 토큰들과 연계되어있으므로 T x T 행렬은 upper triangular term이 모두 0인 (masked) 값을 갖게 한다.
- attention: V가 B x h x T x dh 의 크기를 갖으므로 attention score와 곱해서 그 결과를 내면 B x h x T x dh 가 된다.
그러니까 V 값 중에서 매 시퀀스에서 중요해보이는 값들만 부각되어 출력으로 얻어진다. 각 헤드별로 T x dh의 행렬이 된다.
- concatenated heads: B x T x d –> 각 head별로 분할된 attention을 하나로 합친다.
결국 tokenizing된 값 중에서 몇 개씩 나누어 softmax(attention)을 구할지 결정하고 그렇게 해서 결정된 attention 값을 합쳐서 다시 입력 embedding size로 만들어놓는다.
- linear layer: d x d (사실 d x (d + 1))
- attention output: B x T x d –> B x T x d 의 입력이 들어와서 같은 크기의 데이터블록으로 나온다. 다만 이 값들은 하나의 시퀀스내에서 어떤 것이 중요한지 강조되거나 아니면 약화된 결과 값을 갖게 될 것이다.
생각해보면 시퀀스의 길이(T)가 길면 주어진 길이의 시퀀스에 대해 학습하는 동안 토큰과 토큰과의 관계에 대해서 더 많이 따져보게 될 것이므로 긴 글을 다루는데 적당할 것으로 보여지는데, 이렇게 되면 GPU에 올라가는 데이터 모두가 다 커지게 될 것이므로 나름 잘 고려해봐야 한다. 메모리가 작은 GPU라면 훈련시킬 수 있는 내용의 길이를 길게 가져갈 수가 없다는 말이다.
데이터의 흐름
Transformer의 구조는 대동소이 하다.
Layer norm -> multi-head attention -> layer norm -> Feedforwad net 의 흐름으로 굴러간다. 이렇게 해서 정해진 개수의 layer를 통과해서 나온 결과를 최종적으로 linear norm/matrix multiplication을 해서 내보낸다.
B x T x d의 입력이 들어가서 B x T x d의 출력이 나온다. 마지막의 feedforward net에는 GELU를 activation function쓰는 것으로 알려져있다.
파라미터의 양
이미 설명된 내용으로부터 LLM의 파라미터의 양은 기본적으로 transformer layer를 몇 개를 쌓느냐, 그리고 token embedding size가 얼마가 되느냐, 각각의 transformer의 linear layer의 hidden layer size에 따라 결정된다.
학습이 진행된다면 어디에 어떻게 되는 것일까?
forward 방향으로 입력이 진행한다고 보면,
- 각각의 토큰은 하나의 컬럼 벡터로 주어진다. layer norm을 취하면 대략 방향성만 나타내는 unit vector와 같다고 생각할 수 있을 것 같다.
- Q, K, V 를 구하는 것은 일종의 linear transform이라고 보여진다. 방향성을 나타내는 벡터를 이리 저리 다른 시각으로 바라본다는 뜻으로 볼 수 있을 것 같다.
- 여기서 Q, K의 내적을 구하는 것은 둘이 얼마나 합치하고 있는지 확인하는 것이다. 별로 연관성이 없으면 작은 값, 높으면 큰 값이 될 거다. 그러니까 W_Q, W_V로 선형 변환한 unit vector가 얼마나 일치하는지 본다.
- 내적된 값을 정규화한 뒤에 softmax를 구하여 V에 곱한다. V로 선형변환 한 값 중에서 attention score가 높으면 부각되고 낮으면 작은 값이 된다. 이게 원래 입력에 더해진다.
- 그걸 다시 layer norm한 뒤에 2층짜리 linear layer에 넣는다. 그 결과를 layer norm하기 직전의 값에 더한다.
- 또 생각해보면 하나의 transformer에서 입력에 attention을 더하고 여기에 2 layer network의 값을 더해가는 식의 결과가 나온다. 즉 attention layer와 linear layer에 shortcut이 각각 있는 구조다. 따라서 layer의 수가 많아지더라도 뭔가 입력이 소실되어서 흐지부지 되는 것을 막아주려는 것으로 이해된다. 또 계속해서 normalize하기 때문에 값이 커져서 발산하지도 않는다.
- 이걸 다시 생각하면 그냥 layer의 숫자가 많은 short cut이 있는 MLP의 사이 사이에 attention이라는 layer가 추가된 것으로 생각할 수 있다.
attention을 계산하는 layer는 입력 벡터를 3가지로 변환해서 그 둘간의 유사성이 얼마나 있는지 보고 그것을 통해 나머지를 얼마나 내보내야 할지 결정한다. 이것만 생각하면 뭔가 많이 부족한데, 학습을 할 때는 문장을 가지고 학습을 하게 되므로 사실상 시퀀스 길이가 영향을 미쳐 T x T 행렬에 관해서 따져보게 된다. 즉 T라는 길이를 갖는 문장을 넣었을 때 한 단어씩 앞으로 예측한 결과가 맞아들어가게끔 훈련을 하게 되니까, Q, K, V가 그렇게 한 문장 내에서 단어와 단어의 연결이 어떻게 영향을 미쳐야 하는지 학습된 방향으로 내보내게끔 최적화가 이루어질 것이다. 다시 말해 내가 입력한 문장의 일부분을 받으면 다음에 나와야 할 가장 그럴싸 한 토큰을 (학습에 의해 얻어진) 내보내는 식으로 모든 layer의 weight가 최적화 되어있게 된다. 행렬의 크기나 layer의 size는 얼마나 다양한 경우에 대한 학습이 가능할지를 가늠하게 되는 것이고.
어쨌든, attention + linear layer의 반복이 꽤 많이 이루어지게 되어있으므로, 이 network는 엄청난 차원으로 학습을 시킬 수 있게 되었고 그 수많은 layer가 학습을 통해서 언어의 패턴을 학습하게 되는 것으로 보인다. 차원의 크기가 작으면 많은 정보들이 좁은 공간안에 빽빽하게 모여있는 꼴이 될 것이므로 인접한 정보로 오인하여 오답을 낼 수도 있고 - 사실 이것은 NN의 일반적인 특징이니까 말 할 필요가 없다.
linear layer와 attention layer의 차이
linear layer는 시간적인 관계를 따지지 않으므로 오직 classification(=identification/estimation)을 위해서나 쓸 수 있을 것으로 보여진다. attention layer는 attention score를 계산하는 과정에서 순서가 반영된다. 학습하는 과정에서 문장(시퀀스) 단위로 학습시키기 때문에 Q, K, V를 구하는 transform matrix들은 주어진 문장에서 매 출력 토큰이 하나 앞서 간 토큰이 출력되도록, 즉 하나 앞서간 토큰으로 예측될 확률이 최대화되게끔 Q, K, V를 구하는 행렬이 수렴될 것이기 때문이다.
블록다이어 그램 그 자체로만 볼 때는 Q, K, V는 현재 입력에만 몰두해서 어떤 유사성을 계산하고 하는 것 같아보이지만, 학습과정에서 문장 단위로 학습하면서 최적화하기 때문에 한꺼번에 학습 시키는 시퀀스의 길이에 따라서 attention layer는 순서에 따른 단어와 단어간의 dependence를 가지고 있을 수 밖에 없게 된다.
그렇게해서 얻어진 출력과 shortcut으로 온 입력이 더해지면 원래의 토큰이 특정 방향으로 이동하게 된다. 그 결과가 linear layer를 통과하게 되면 수많은 경우 중 하나로 classified되어 출력된다. 이 값은 다시 shortcut에 더해진다. 출력은 norm(norm(입력) + attention layer output) + FF layer output의 모양이 된다.
따라서, 이 출력은 쉽게 말해서 원래 입력 + 문장내에서 dependence에 결정된 값 + 현재입력+문장에서의 dependence를 가지고 classified된 보정값으로 나오게 된다. 그러니까 입력이 2단계에 걸쳐서 특정 방향으로 이동한다. 이게 계속해서 layer를 쌓게 되면 현재 입력된 토큰은 계속해서 여러 단계 변화하여 엄청나게 많은 차원을 통해서 관찰하고 classified된 token으로 변화한다. 문장이 길면 길수록 아마도 출력으로 나오게 될 토큰의 확률은 더 높아지게 될 것이다.
그러니까, attention layer는 문장 내에서 순서, 그리고 단어와 단어와의 관계를 반영한다고 이해하면 될 것 같다. 왜 이런 방법을 찾아내게 되었는지, 이와 다른 방법을 (기왕이면 복잡도가 낮은) 도입하면 안될까 하는 생각을 하게 된다. linear layer의 경우는 drop out을 한다거나 해야 복잡도를 조금 낮출 수 있겠지만 드라마틱 할 수가 없는 반면, attention layer는 나온지가 얼마 안되었기 때문에 개선의 여지가 있다고 생각한다. 그래서, 여기서 계산량을 줄이는 방법으로 히트 (flash attention, deepseek)를 쳤다고 본다.
transformer layer간 연결: 직렬 연결
그냥 생각하면 transformer layer를 직렬로 연결해야되니까 이게 어떻게 병렬화가 되겠느냐 할 수 있을텐데, 입력을 하나의 단어가 아닌 문장으로 입력하게 되면 각각의 토큰에 대해서 독립된 transformer를 돌리는 식으로 동작하게 되므로 병렬화가 가능하다. 물론 이게 가능해진 것은 attention layer에서 문장에서의 단어 순서를 따지고 있기 때문이다.
이 모델을 어떻게 생성하는데 사용하지?
지금의 모델 구조는 문장을 학습시키는데, 주어진 내용으로부터 원하는 다음 토큰을 학습하는 방식으로 만들어졌다는 사실을 이용한다. 즉, 어떤 문장을 입력하면 학습시에 주어졌던, 그것과 가장 유사한 내용을 갖는 내용을 출력하도록 되어있다. 만일 질문에 대한 대답을 얻게끔 학습시킨다면 질문과 답변을 같이 놓고 학습을 시키면 된다. 그러니까 질문을 모델에 넣어주면 모델에서 나오는 토큰을 계속해서 더 해가면서 모델에 던져주는 식으로 진행하면 모델은 계속해서 새로운 토큰을 내보내는 식으로 진행한다. 별도의 식별자 (eos (end of sequence))가 나올 때까지 계속 진행한다.
종합하자면
내가 관찰한 바로는,
- GPT 모델은 transformer layer를 쌓아올린 모델이다. 기능은 일종의 predictor 역할을 한다. 문맥을 파악하여 다음 단어를 내주는, 또 그걸 이용하여 더 높은 확률로 맥락이 있는 출력을 내어주는 모델이다.
- 이걸 잘 보면 attention layer + feedforward layer(2 layers)의 반복이고 둘다다 shortcut이 있다.
- MLP에 short cut이 있는 layer를 쌓아두기만 하면 현재 입력에 대한 다차원에서 복잡한 classification만 반복할 뿐, 사람의 언어에서 처럼 단어의 순서가 명확한 시퀀스에 대한 분류/추청/예측을 할 수가 없는 것에 반해, 문장 안에서 단어와 단어와의 관계 (attention)에 대한 정보를 가지고 있는 layer를 하나 더 두어서 그것을 이미 학습해놓은 패턴/맥락에 따른 문장/단어 예측이 가능해진 것이다.