기왕 이렇게 된 김에: Deepseek model...
on
DeepSeek이 나와서 주식이 떡락하던 날을 나는 기억한다.
정말로 무력하게 느껴진 것은 DeepSeek이 엄청난 장점이 있어서….블라블라….그래서 주식이 떡락했다 라는 말을 제대로 이해할 수 없었다는 거다.
왜!!??? 왜 좋은지 알 수 없었다…
글쎄 내가 너무 늙어서 새로운 것을 이해할만한 기력이 없다거나, 아니면 너무 어려서 앎이 짧아서 그랬다면 모를까, 나도 나름 배운 사람인데 내용을 자세히 알 수도, 이해할 수도 없었다는 사실이 정말로 날 우울하게 만들었다.
기왕에 transformer에 대해서 희끄무리하게 윤곽을 파악하게 된 김에 DeepSeek에 대해서 알아보기로 하자.
아래의 그림이 DeekSeek의 block diagram이다.
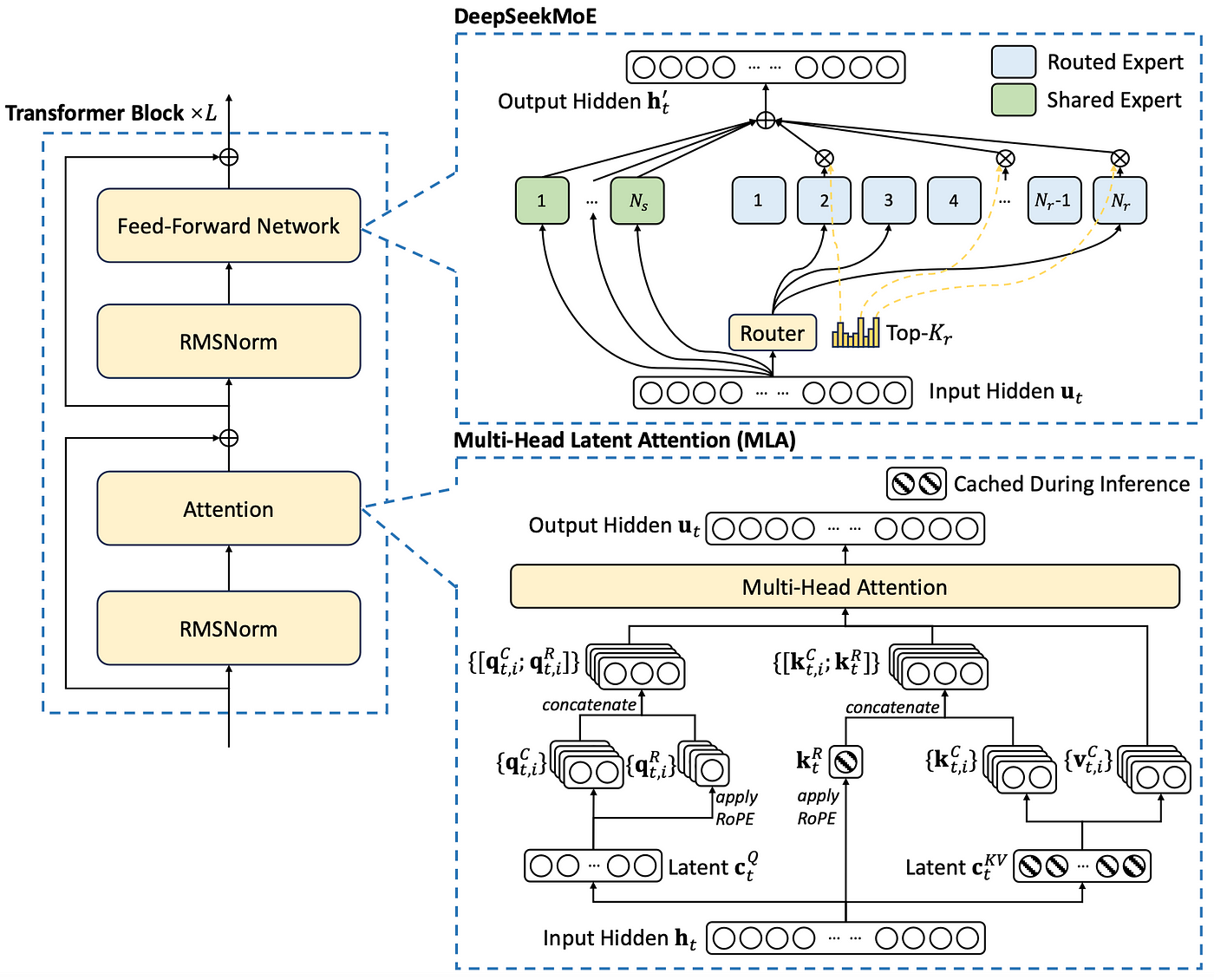
내가 파악한 바로는 DeepSeek에서는 기존 모델 (GPT 모델)대비 2가지 부분을 개선했다.
- Multihead attention 부분의 계산량과 메모리 크기를 줄임
MLA (multi-head latent attention)이란 걸 정의했다. 이게 무슨 뜻이냐고? multi-head 잠재 어텐션? 뭐 이런 뜻을 주려고 한 것 같은데, 어쨌든. 기본 아이디어는 Q/K/V를 계산할 때 matrix의 size가 embedding size (d) x d로 되어있는 게 좀 over했다 라고 생각해서 이걸 downsizing하는 matrix를 정하고 그걸 곱해서 크기를 줄여놓은 걸 latent라고 부른 것이다. 어쨌든 downsizing을 위한 projection matrix를 곱해서 rank를 줄인 후에 attention을 계산하고 출력단에서는 이것을 다시 upsizing하는 projection matrix을 곱해서 내보내게 된다.
이것은 충분히 생각할 수 있는 문제인데, 이것을 실행해서 성능의 차이가 없다는 것을 보여줬다는 게 중요한 기여라고 생각한다. 아직 이해가 좀 어려운 것은 Q/K/V 중에서 K와 V는 grouping을 했다는 거다. 둘을 묶어서 처리하고 KV는 따로 caching을 해서 추론 성능을 올렸다.
나머지 프로세스에는 차이가 없다. - MOE (mixture of experts)
이런 말 표현이 어디서 출발한 것인지, 아마도 논문에서 사용한 표현 같은데, 아마도 shared experts와 routed experts를 같이 사용한다는 데서 온 것 같다.
내가 해석하기로는 그냥 단순하게 size가 큰 linear layer를 쓰면 그것의 크기에 비해 얻어지는 성능의 향상이 크질 않으니 작은 size의 linear layer를 여러 개 두고 그것을 스위칭하는 (논문상의 표현으로는 routing이라고 썼다) 블럭을 하나 두어서 경우에 따라 선택해서 사용하게끔 한 것으로 이해한다.
재미있는 것은 총 61개의 layer 중에서 처음 3개는 MoE가 없는 일반적인 linear layer 2개가 MHA뒤에 따라붙는 일반적인 구조이고 나머지 58개의 layer는 MoE를 두고 있다는 거다.
이를테면 1024 x 1024로 하던 걸 2 x 512 x 512를 하는 게 계산량 측면에서는 훨씬 이득이다. 대개 feedforward network의 크기는 좋은 성능을 얻으려고 하면 굉장히 커지게 된다. 아마도 이것을 이렇게 downsizing하게 된 것 또한 수많은 실험을 통해서 얻어진 결과가 아닐까 한다.
- 그외의 성능 향상
Multi-token prediction: transformer를 몇 개 더 두고 두번째 3번째 앞 토큰까지 예측하는 방법이다. 물론 첫번째 예측 결과는 본래의 transformer model에서 가져와서 본래의 주 모델 대비 비교적 간단한 구조로 두번째 세번째 토큰을 예측 해내겠다는 말이다. RoPE (Rotary of Positional Embedding)과 같은 특징이 있는데, 사실 아직 거기까진 진도가 못 나갔다. 이제 겨우 MHA과 transformer의 윤곽만 희미하게 보고 있는 상황이기 때문에. 어쨌든 이 구조가 정말로 기존의 구조에 대비해서 계산량과 메모리 사용률을 크게 줄이면서도 좋은 성능을 낼 수 있는지는 실험을 통해서야만 확인할 수 있다.
이것은 neural network의 비애라고 생각한다. 너무 복잡하고 많아서 이론적으로 분석하기 어렵다는 것. 그냥 잘 되면 잘 되는 구나, 안되면 고쳐보고 또 실험하고 실험하는 것.
그나마, GPU가 있어서 얼마나 다행인가? 이런 구조와 틀 (매우 사이즈가 큰 행렬을 계속 곱해나가야 되는 경우) 에서는 DSP도 별 도움이 안되고 multicore CPU 머신을 네트워크로 묶는 것도 효율적이지 못하다. 병렬 계산을 엄청해야 되고 그 각각의 요소들 간에 데이터를 주고 받는 게 엄청나게 중요한데, CUDA는 그런 의미에서 이런 구조에 딱 들어맞는 아키텍쳐이다보니 다른 방법과 비교를 할 수가 없다.